Hanqing Zeng
Research Scientist
Meta AI
Biography
I am a Research Scientist at Meta AI, where I work on SoTA LLMs and graph learning models for web-scale social recommendation. Prior to Meta, I obtained my Ph.D. in Computer Engineering at University of Southern California, advised by Prof. Viktor Prasanna. My thesis focused on improving the scalability, accuracy and efficiency of large scale Graph Neural Networks. I designed new neural network models, learning algorithms as well as hardware systems for scalable training and inference. My work has led to publications in top venues in both AI (ICLR, NeurIPS, ICML, etc.) and systems (FPGA, VLDB, TRETS, etc.). I have received outstanding / top reviewer awards from ICLR, NeurIPS and ICML.
I am broadly interested in problems in ML and system design. Please reach out to me via my personal email if you’d like to discuss.
- Graph representation learning
- Parallel & distributed computing
- Hardware accelerator design
-
PhD in Computer Engineering, 2022
University of Southern California
-
Bachelor of Engineering, 2016
University of Hong Kong
Experience
Responsibilities include:
- Developed graph engine to support large scale GNN computation on production data
- Developed new GNN models for heterogeneous graphs
Responsibilities include:
- Integrated state-of-the-art minibatch GNN training methods (e.g., GraphSAINT) into internal infrastructure
- Developed new GNN models for orders of magnitude improvements in scalability (shaDow-GNN)
Achievements:
- Authored or Coauthored 20+ papers (1 best paper award + 2 best paper candidates)
- Mentored 5+ junior PhD or Master students, and helped them publish their first papers
- Contributed to 5+ DARPA and NSF projects
- Serving as a reviewer or PC member for 20+ top conferences and journals (outstanding reviewer award for ICLR 2021 and ICML 2022; top reviewer award for NeurIPS 2022)
Featured Publications
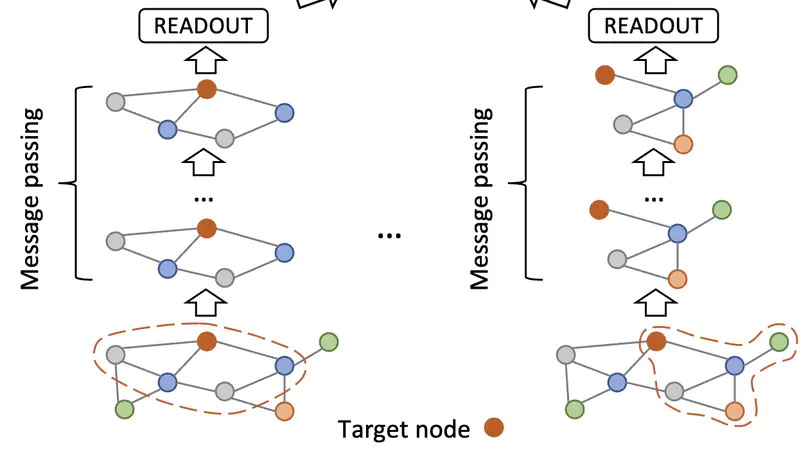
Old GNN models + New data perspective = Surpassing 1-WL, Avoiding oversmoothing & Overcoming neighborhood explosion
-
Official code: https://github.com/facebookresearch/shaDow_GNN
-
PyTorch Geometric implementation: https://pytorch-geometric.readthedocs.io/en/latest/modules/loader.html#torch_geometric.loader.ShaDowKHopSampler
-
Deep Graph Library implementation: https://docs.dgl.ai/en/latest/_modules/dgl/dataloading/shadow.html
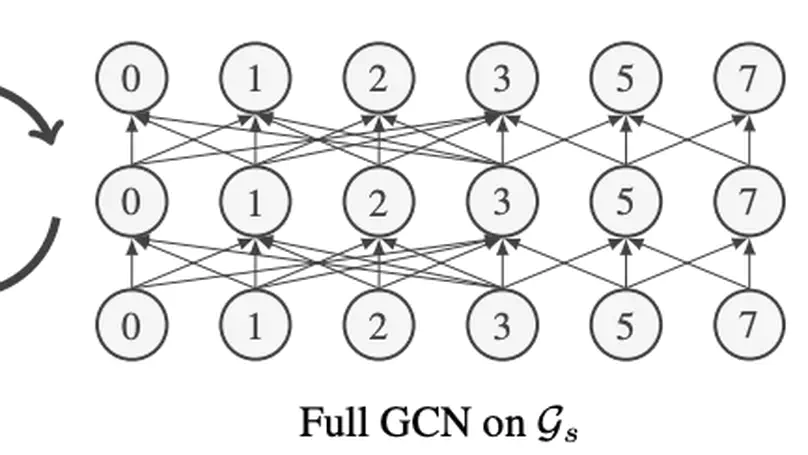
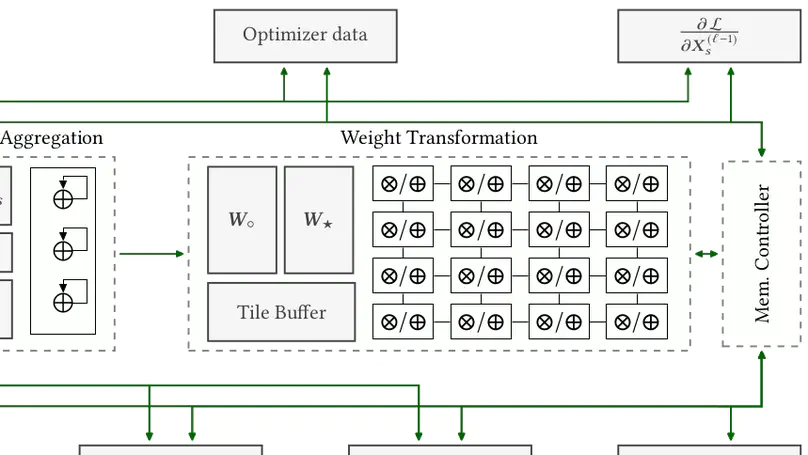
Recent Publications
Contact
- zhqhku@gmail.com
- 1 Meta Wy, Menlo Park, CA 94025
- DM Me